Incident Management
Beschreibung
Das Incident Management bzw. Störungs Management stellt den Prozess, die Werkzeuge und das Konzept für eine schnelle Störungsbehebung zu einem vereinbarten Service bereit. Der Incident Management Prozess ist verantwortlich für die regelmäßige Information des Benutzers bzw. Users. Der Service Desk ist für die Annahme, das Akzeptieren, die Klassifikation und das Abwickeln der Störungen bzw. der Incidents verantwortlich.
Ziele
Ziel des Prozesses ist es, Störungen im Rahmen der vereinbarten Service Level schnellstmöglich zu beheben, um negative Auswirkungen auf Geschäftsprozesse so gering wie möglich zu halten.
Rollen & Funktionen
Incident Management spezifische Rollen
Statische Prozessrollen
Incident Management Prozessverantwortlicher (Process Owner)
Der Prozessverantwortliche ist verantwortlich für das Definieren der prozessstrategischen Ziele und das Bereitstellen aller erforderlichen Ressourcen. Siehe auch Continual Process Improvement Management für eine detaillierte Beschreibung dieser Aktivitäten. Meist gibt es nur einen Prozess Verantwortlichen (Process Owner) für alle Service Management Prozesse.
Incident Management Prozess Manager (Incident Manager)
Manager des gesamten Prozesses, verantwortlich für die Prozesseffektivität und -effizienz. Siehe auch Continual Process Improvement Management für eine detaillierte Beschreibung dieser Aktivitäten.
Dynamische Prozessrollen
Diese Rollen werden während der Ausführung des Incident Management Prozesses dynamisch belegt.
Incident Verantwortlicher (Owner)Das Attribut im Record (Ticket) beinhaltet den Namen der Person oder Gruppe die gegenwärtig für den Incident (aber NICHT für den Incident Management Prozess) rechenschaftspflichtig (accountable) ist. Der Incident Verantwortliche kann durch eine Hierarchische Eskalation verändert werden.
Incident Bearbeiter (Agent)
Das Attribut im Record (Ticket) beinhaltet den Namen der Person oder Gruppe, die gegenwärtig für eine Aktivität oder einen Task innerhalb des Lebenszyklus eines Requests verantwortlich ist. Der Incident Bearbeiter kann durch eine funktionale Eskalation verändert werden, wenn dies die Regeln erlauben.
Servicespezifische Rollen
Rollen, die von einem betroffenen Service abhängen, findet man in der Service Beschreibung (Description). Die Service Beschreibung inklusive der servicespezifischen Rollen, wird vom Service Portfolio Management geliefert.
Service Experte und Service Spezialist
Er übernimmt die dynamische Rolle des Incident Bearbeiters (Agent) nach einer Weiterleitung (2nd/rd Level) .
Service Verantwortlicher (Owner)
Dies ist die Person, die für einen Service, wie er in der Service Beschreibung definiert ist, verantwortlich ist. Sie übernimmt bei einer hierarchischen Eskalation die Rolle des Incident Verantwortlichen, kann aber auch als Incident Bearbeiter (Agent) eingesetzt werden.
Kundenspezifische Rollen
Rollen, die von den betroffenen Kunden abhängen, findet man in den Service Level Agreements (SLA). Das Service Level Agreement für kundenspezifische Rollen wird durch das Service Agreement Management gepflegt.
Kunden (customer)
Kunden des betroffenen Service mit einem gültigen SLA
Benutzer (User)
Verbraucher des Services und ist zur Abgabe von Service Requests durch den Kunden berechtigt
Service Desk
Funktion die die dynamische Rolle des Incident Bearbeiters (Agent) anfänglich übernimmt (1st Level), sofern dies nicht anders definiert ist. Die Funktion kann auch servicespezifisch definiert sein.
Informationsdokumente
Dieser Bereich beschreibt Dokumente, die während der Ausführung eines Incident Managements Prozesses entstehen und Dokumente, die zur Ausführung des Prozesses benötigt werden, sofern sie nicht von einem anderen Prozess bereitgestellt werden müssen und daher in der diesbezüglichen Prozessbeschreibung definiert werden
Incident Record
Der Incident Record ist das Informationsdokument, das alle für das Management relevanten Informationen inklusive der Historie eines spezifischen Requests (Prozessinstanz) enthält. Beim Durchlaufen des Prozesses wird er mit Informationen gefüllt. Nach Abschluss der Prozessinstanz darf der Record nicht mehr verändert werden.
- Incident ID (Ticket ID) – eindeutige Bezeichnung (Unique identifier)
- Status – Zustand innerhalb des Lebenszyklus einer Störung. Der Statusübergang findet statt, wenn eine Kontrollaktivität positiv passiert wurde.
- Betreff (Subject) – Kurzbeschreibung der Störung
- Externe Incident Beschreibung (external Request Description) – für den Benutzer sichtbare Beschreibung der Störung
- Interne Incident Beschreibung (internal Request Description) – Interne Beschreibung mit Ergänzungen zur externen Beschreibung
- Incident Verantwortlicher (Owner)
- Incident Bearbeiter (Agent)
- Kunde (Customer) – Kunde(n), die von dieser Störung betroffen sind.
- Benutzer (User) – der oder die Benutzer, die von dieser Störung betroffen sind.
- Melder – Name der Person, die den Incident auslöst, oft identisch mit Benutzer
- Services – Service(s), die von dieser Störung betroffen sind
- Sub-Services – Sub-Service(s), die von dieser Störung betroffen sind
- SLA – Informationen zum relevanten Service Level Agreement (SLA)
- betroffenes CI – Hardware oder Software CI, das von der Störung betroffen ist
- Priorität – Priorität auf Basis der Auswirkung und Dringlichkeit
- Auswirkungen (Impact) – Auswirkung eines Incident z.B. Anzahl der betroffenen Benutzer
- Dringlichkeit (Urgency) – Dringlichkeit wird durch den relevanten Service Level Bzw. das relevante Service Level Agreement SLA definiert
- Endtermin (Deadline) – Der Endtermin (Zeitpunkt) hängt von der Priorität der Störung ab
- Medium – beschreibt das Medium, das zum Auslösen der Störung genutzt wurde, wird auch als bevorzugter Informationskanal für die weitere Kommunikation verwendet.
- Prüfungsergebnis der generellen Checklisten (Incident Model)
- Prüfungsergebnis der servicespezifischen Checklisten (Incident Model)
- Probleme oder Fehler – Liste der Probleme oder Fehler, die in Bezug zu dem Incident stehen
- Übergangslösung (workaround)
- ausgelöste Changes – Liste, der durch den Incident ausgelösten Veränderungen
- Testergebnisse
- Externe Lösungsbeschreibung (external Solution Description) – für den Benutzer sichtbare Beschreibung der Störung und der Dokumentation der einzelnen Schritte
- Interne Lösungsbeschreibung (internal Solution Description) – Interne Lösungsbeschreibung mit Ergänzungen zur externen Lösungsbeschreibung
- Weiterleitungen – Anzahl der funktionalen Eskalationen einer Störung
- Hierarchische Eskalation – Anzahl der hierarchischen Eskalationen einer Störung
- Anmerkungen – Informationsfeld, in dem die einzelnen Arbeitsschritte kommentiert werden und zusätzliche Informationen hinzugefügt werden können
- Abschluss Anmerkung (Closing Comment) – zusätzliche Information bezogen auf die Abschlussaktivität
- Anhänge (Attachments) – andere Dateien, Dokumente, Screenshots etc.
Incident Meldung (Notification)
Information, die dem Melder und/oder Benutzer aktiv oder passiv zur Verfügung gestellt wird.
- Incident ID
- Status
- Betreff
- Priorität
- Endtermin
- Externe Incident Beschreibung
- Externe Lösungsbeschreibung
Schlüsselkonzepte
Major Incident Handling
Ein Major Incident ist eine Störung mit der Priorität „1“. Um die Prozessausführung zu beschleunigen, wenn man es mit einem Major Incident zu tun hat, gelten folgende spezielle Prozeduren:
- Der Serviceverantwortliche übernimmt Verantwortlichkeit für die Störung vom ServiceDesk. Er ist nun verantwortlich für den Incident.
- Er muss servicespezifische Regeln für den weiteren Umgang mit Major Incidents beachten.
Priorität
Die Priorität ist eine Steuergröße des Prozesses und unterstützt den Incident Manager beim effizienten Einsatz der Ressourcen (z.B. Personal, Kapazität, Zeit). Die Priorität ist ein Produkt aus Auswirkung und Dringlichkeit. „1“ ist die höchste Priorität
Incident Klassifikation
Der Incident muss klassifiziert werden und ein Endtermin muss definiert werden. Diese Klassifikation ist eine fortlaufende Aktivität bis der Incident behoben ist. Der Endtermin muss so festgesetzt werden, dass sichergestellt ist, dass das vereinbarte Service Level nicht übertreten wird.
Incident Lebenszyklus
| Status | Status | Beschreibung |
| neu | new | Ein neuer Incident wird identifiziert und in einem Record dokumentiert |
| registriert–angenommen | recorded-accepted | Ein neuer Incident ist registriert, wird angenommen und enthält alle notwendigen Informationen. |
| registriert-abgelehnt | recorded-rejected | Ein neuer Incident ist zwar registriert, wird aber nicht angenommen. Die Begründung ist dokumetiert. |
| klassifiziert | classified | Alle wichtigen Steuergrößen sind bestimmt; z.B. Priorität, betroffene Services und das Service Level Agreement (SLA). |
| unterstützend-erfolgreich | supported-successful | Der Support durch den Bearbeiter hat zu einer Lösung geführt. |
| unterstützend-nicht erfolgreich | supported-failed | Der Support durch den Bearbeiter hat zu keiner Lösung geführt. Es muss weitergeleitet werden. |
| wiederhergestellt | recovered | Der Incident ist aus Sicht des Bearbeiters mit oder ohne Unterstützung des Change Managements behoben aber noch nicht getestet. |
| getestet-fehlgeschlagen | tested failed | Der Incident hat die erforderlichen Tests nicht erfolgreich bestanden. |
| getestet-erfolgreich | tested successful | Ein Incident hat die erforderlichen Tests bestanden. |
| abgebrochen | canceled | Ein Incident, der den Lifecycle nicht komplett durchlaufen hat. |
| beendet–nicht erfolgreich | closed–failed | Der Incident konnte nicht erfolgreich geschlossen werden und muss erneut untersucht werden. |
| beendet-erfolgreich | closed–successful | Der Incident konnte erfolgreich geschlossen werden. |
Hierarchische Eskalation
Eine hierarchische Eskalation muss ausgelöst werden, wenn die Störung auf einem “regulären” Weg nicht erfüllt werden kann. Dieser Fall tritt ein, wenn folgende Punkte absehbar sind:
- Die verfügbaren Ressourcen reichen nicht aus.
- Die Vereinbarungen z.B. Endtermin im relevanten Service Level bzw. SLA können nicht erfüllt werden.
Eskalationslevel
Sofern im Service Level bzw. in den Service Level Agreements nicht anders definiert, gelten folgende Eskalationsstufen:
- Erste Eskalationsstufe: Incident Manager
- Zweite Eskalationsstufe: Incident Manager und Service Verantwortlicher. Der Serviceverantwortliche muss entscheiden, ob weitere Personen (Kunde, Kundenverantwortliche) informiert werden müssen.
Eine Eskalation kann in jedem Bearbeitungsschritt erfolgen. Die Eskalation muss eingeleitet werden, wenn 75 % der geplanten Dauer eines Incident aufgebraucht sind. Die geplante Dauer errechnet sich durch den geplanten Endtermin des Auslösens der Störung. Bei jeder hierarchischen Eskalation wird der entsprechenden Zähler im Record um eins erhöht.
Prozess
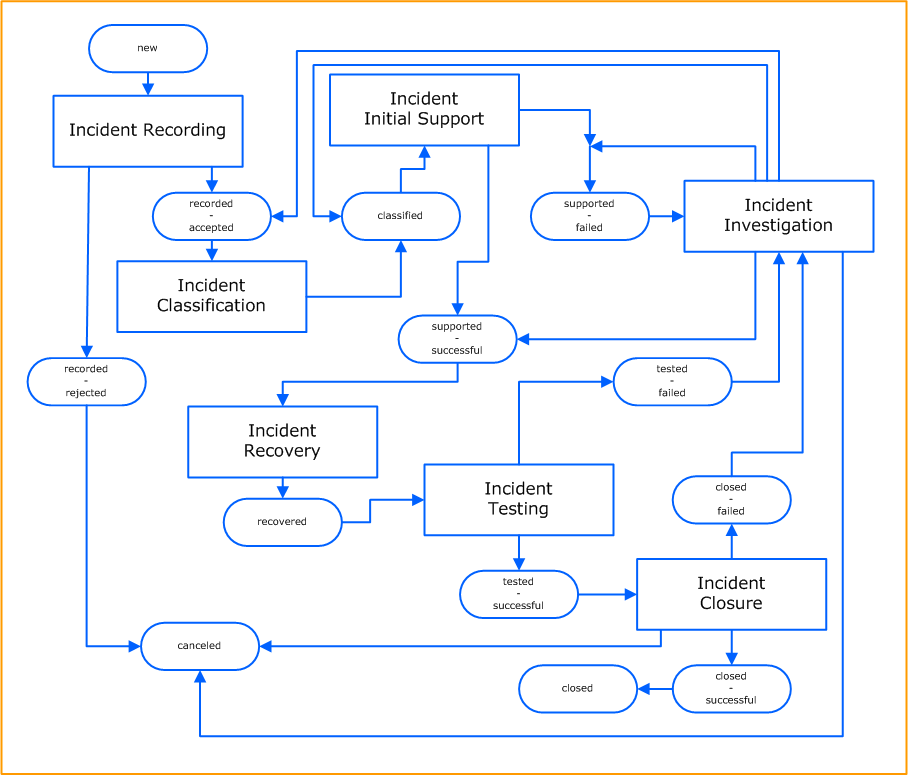
Prozessüberblick
Diese Abbildung zeigt den Incident Management Prozess, seine Aktivitäten und die dazugehörigen Kontrollaktivität (Status).
Kritische Erfolgsfaktoren
Kritische Erfolgsfaktoren (Critical Success Factors (CSF)):
- Registrierung aller Störungen als Record
- Kontinuierliche Überprüfung der Incident Klassifikation und des geplanten Endtermins
- Kooperation mit dem Change Management
- Kooperation mit dem Service Portfolio, Service Level und Service Level Agreements Management
- Hohe Benutzer- und Kundenzufriedenheit
- Hoher Anteil an erfüllten Service Requests innerhalb der vereinbarten Zeit
- Incident Überlastung und Rückstand (Incident overload and backlog)
- Verlässliche Daten vom Configuration Management
- Ausführliche “Knowledge Database”, welche Probleme, Known Errors, Lösungen und Übergangslösungen beinhaltet
- Automatisiertes Ticket Tracking System
Key Performance Indicators (KPI)
Definition
- offene Störung= alle Störungen die NICHT den Status „abgeschlossen“ oder „abgebrochen“ haben
- gelöste Störung= alle Störungen die den Status „getestet – erfolgreich“ haben
- geschlossene Störung = alle Störungen die den Status „abgeschlossen“ oder „abgebrochen“ haben
- Incident Registrierungsdauer = ZS „registriert – angenommen“ – ZS „neu“ oder ZS „registriert – abgelehnt“ – ZS „neu“
- Incident Klassifikationsdauer = ZS „klassifiziert“ – ZS “ registriert – angenommen“
- Incident Initial Support Dauer = (ZS „unterstützend – erfolgreich“ – ZS „klassifiziert“) oder (ZS „unterstützend – nicht erfolgreich“ – ZS „klassifiziert“)
- Incident Investigation Dauer = (ZS “ unterstützend – erfolgreich“ – ZS „unterstützend – nicht erfolgreich“) oder (ZS „abgebrochen“ – ZS „unterstützend – nicht erfolgreich“) oder (ZS “ klassifiziert“ – *ZS „unterstützend – nicht erfolgreich“) oder (ZS “ registriert – angenommen “ – ZS „unterstützend – nicht erfolgreich“
- Incident Recovery Dauer = (ZS “ wiederhergestellt“ – ZS „unterstützend – erfolgreich“)
- Incident Test Dauer = (ZS „getestet – erfolgreich“ – ZS „wiederhergestellt“) oder (ZS „getestet – nicht erfolgreich “ – ZS “ wiederhergestellt“)
- Incident Abschlussdauer = ZS „abgeschlossen“ – ZS “ getestet – erfolgreich“ oder ZS „abgebrochen“ – ZS “ getestet – erfolgreich „
- Lösungsdauer Incident = Incident Registrierungsdauer + Incident Klassifikationsdauer + Incident Initial Support Dauer + Incident Investigation Dauer + Incident Recovery Dauer + Incident Test Dauer
- Gesamtdauer des Service Requests = Lösungsdauer Incident + Incident Abschlussdauer
Die Dauer jeder Aktivität ist via Zeitstempel (ZS) beim Setzen des Kontrollstatus messbar.
Auswertung
- Anzahl der aktuell offene Störungen
- Anzahl der durchschnittlichen offenen Störungen pro Tag/pro Monat
- Anzahl der geöffneten Störungen pro Tag/pro Monat
- Anzahl der gelösten Störungen pro Tag/pro Monat
- Anzahl der geschlossenen Störungen pro Tag/pro Monat
- Anzahl erfüllte Störungen (Lösungsdauer der Störungen <= vereinbarte Lösungsdauer für alle gelösten Störungen pro Tag/pro Monat)
Ausgewertet wird die maximale, minimale und durchschnittliche Zeitdauer pro Kunde und/oder pro Service.
Prozessauslöser (Trigger)
Ereignisgetriebener Auslöser (event triggered)
Eine Störung kann durch einen Benutzer (User) oder einen Event ausgelöst werden.
Zeitgetriebener Auslöser (Time Trigger)
Incidents können nicht periodisch ausgelöst werden.
Prozessspezifische Regeln
- Jeder Incident löst das Entstehen eines neuen Incident Records aus.
- Der Incident Bearbeiter ist verantwortlich für das Dokumentieren jeder Aktivität im Incident Record.
- Der Incident Verantwortliche muss den Incident Bearbeiter kontrollieren.
- Der Incident Verantwortliche und der Incident Bearbeiter können ihre Pflichten nur übertragen, wenn die neue Person oder Gruppe damit einverstanden ist.
- Der neue Incident Verantwortliche oder Incident Bearbeiter muss dann dementsprechend im Incident Bericht festgehalten werden.
- Der Incident Verantwortliche und der Incident Bearbeiter sollten, wenn möglich, eine Person und nicht eine Gruppe sein.
- Im Falle eines Major Incidents:
- Das Intervall für Benutzer und/oder Melder Information sollte auf “eine Stunde” während Geschäftszeiten gesetzt werden
- Die Servicebeschreibung sollte von weiteren Personen, die informiert werden, geprüft werden.
- Die Servicebeschreibung, die Service Level und die Service Level Agreements sollten auf weitere zu beachtende Regeln geprüft werden.
- Der Service Verantwortliche wird zum Incident Verantwortlichen bestimmt.
Prozessaktivitäten
Incident Registrierung
Der Record wird erstellt und es wird überprüft ob der Melder die Störung melden darf. Alle Informationen des Antragstellers sind in dem Record zu dokumentieren.
Aktivitätsspezifische Regeln
- Die ID wird erzeugt.
- Der Status wird auf „neu“ gesetzt.
- Der Melder wird auf die Person gesetzt, die den Incident ausgelöst hat.
- Der Bearbeiter wird auf das „Service Desk“ gesetzt, falls keine Person verfügbar ist.
- Der Verantwortliche wird auf „Service Desk“ gesetzt, falls keine Person als Verantwortlicher verfügbar ist.
- Der Betreff wird ausgefüllt.
- Die interne und externe Beschreibung wird ausgefüllt. Das Ticket muss eine aussagekräftige Beschreibung des erwünschten Requests enthalten, genauso wie eine verständliche Aussage bzgl. des Grundes des Requests.
- Der Kunde wird gesetzt.
- Der Benutzer wird gesetzt.
- Das Medium wird dokumentiert.
- Gegebenenfalls werden Dokumente angehängt.
- Gegebenenfalls werden Anmerkungen dokumentiert.
Incident Klassifikation
Die Aktivität Klassifizierung ist ausschlaggebend für den Erfolg des Incident Management Prozesses. In ihr werden die Steuergrößen bestimmt. Der erste Schritt ist, den betroffenen Service zu selektieren und die entsprechenden SLAs zu bestimmen. Danach muss die Priorität in Einklang mit den relevanten SLAs definiert werden. Anderen Steuergrößen werden ebenfalls festgelegt. Der Incident Rekord wird mit den Werten des Anrufberichts vervollständig.
Aktivitätsspezifische Regeln
- Service und Sub-Service bestimmen.
- Relevante SLA bestimmen.
- Priorität durch Auswirkung und Dringlichkeit bestimmen.
- Endtermin bestimmen.
- Betroffene CI bestimmen.
- Gegebenenfalls Dokumente anhängen.
- Gegebenenfalls Anmerkungen dokumentieren.
- Informationen an den Anwender bzw. Melder geben.
Incident Initial Support
Diese Aktivität prüft, ob es einen ähnlichen Incident gibt oder gab und ob für den Incident schon Lösungsbeschreibungen existieren. Klassifizierte Incidents werden geprüft, bezugnehmend auf die folgende generelle Checkliste:
- Gibt es offene Incidents mit derselben Störungsmeldung?
- Gibt es geschlossene, dokumentierte Incidents mit derselben Störungsmeldung?
- Gibt es offene Probleme, die zur Störungsmeldung passen?
- Gibt es bekannte Workarounds?
- Gibt es kürzlich durchgeführte Changes, die den selben Service betreffen?
Wenn eine dieser Fragen positiv beantwortet werden kann, kann das die Bearbeitungszeit reduzieren. Sollten ähnliche Incidents gefunden werden, so sollte ein Incident Verantwortlicher für alle diese Incidents bestimmt werden. Das vermeidet, dass zwei verschiedene Owner (Verantwortliche) einen ähnlichen Incident bearbeiten. Wenn Incidente gleichzeitig auftreten, haben sie meist dieselbe Ursache und können daher zusammengelegt werden. Eine gute Dokumentation über Lösungen und gelöste Incidents kann helfen, die Bearbeitungszeit für neue Incidents herabzusetzen. Falls keine der Fragen beantwortet werden kann, muss eine spezifische Checkliste durchgegangen werden. Diese servicespezifische Checkliste wird in der Servicebeschreibung bereitgestellt. Abhängig von der Qualität des Initial Support, werden weniger Incidents zum Service Experten (2nd Level) weitergeleitetet werden müssen. Diese Beziehung zwischen Incidents und Problemen ist nur möglich, wenn ein Problem Management Prozess existiert. Bekannte Workarounds von Incidents können auch die Bearbeitungszeit neuer Incidents verbessern.
Aktivitätsspezifische Regeln
- Ausführen der Anweisungen auf der generellen Checkliste
- Ausführen der Anweisungen auf der servicespezifischen Checkliste
- Dokumentieren der Ergebnisse
- gegebenenfalls Dokumente anhängen
- gegebenenfalls Anmerkungen dokumentieren
- Wenn keine Lösung gefunden wurde, muss das Ticket weitergeleitet werden:
o Ändern des Bearbeiters auf die neue Person oder Gruppe, die für den klassifizierten Service einen 2nd Level Support erbringt (Gruppe der Service Expertenaus der Service Beschreibung).
o Erhöhen des Zählers „Weiterleitung“ um 1
Incident Investigation
Incident Investigation (Fehlerermittlung) ist die komplexeste Aktivität im Management Prozess. Der Incident wird untersucht, indem die zur Verfügung stehenden Informationen bezüglich der Symptome genutzt werden, mit der Absicht, eine schnelle Lösung für den Incident und eine Wiederherstellung des/r unterbrochenen Services zu finden. Die erste Aktion in dieser Aktivität ist es, zu prüfen, ob die Klassifikation, speziell die Bestimmung des Services, korrekt abgeschlossen wurde. Falls nicht, wird der Incident zur erneuten Klassifizierung zum Service Desk zurückgegeben. Falls die Klassifikation korrekt war, werden die Ergebnisse der generellen und spezifischen Checkliste durchgesehen. Falls der anfängliche Support falsch oder nicht vollständig durchgeführt wurde, werden die Incidents zur Nachbearbeitung ebenfalls zum Service Desk zurückgegeben. Falls beide Überprüfungen erfolgreich durchgeführt wurden, beginnt der 2nd Level Support (oder 3rd Level Support) mit den Nachforschungen. Wenn eine Lösung gefunden ist, wird die Aktivität „Instandsetzung“ ausgeführt, dann kann das Incident Ticket zum Service Desk zurückgegeben werden. Dies muss aber nicht geschehen. Falls keine Lösung gefunden wird, kann das Ticket funktional zu einem Spezialisten eskaliert werden.
Aktivitätsspezifische Regeln
- Falls die Klassifikation NICHT korrekt war
o Zuweisen des Tickets an den vormaligen Bearbeiter zur erneuten Klassifizierung - Falls der anfängliche Support NICHT korrekt war
o Zuweisen des Tickets an den vormaligen Bearbeiter zur Verbesserung der Vorprüfung - Störung untersuchen
- Falls keine Lösung gefunden wird:
o informiert der Bearbeiter den Incident Verantwortlichen
o informiert der Bearbeiter den Service Verantwortlichen
o bestimmt der Bearbeiter einen passenden Service Spezialisten und leitet die Störung weiter
Falls ein Lösung gefunden wird und die nächsten Aktivitäten (Wiederherstellen, Testen..) vom Service Desk durchgeführt werden sollen, bestimmt der aktuelle Bearbeiter einen neuen Bearbeiter aus dem Service Desk.
Incident Instandsetzung
Wenn eine Lösung gefunden wurde, sind unterschiedliche Instandsetzungsmaßnahmen möglich. Falls ein Change benötigt ist, muss der Change Management Prozess ausgelöst werden. Andernfalls kann entweder der Bearbeiter die Instandsetzung durchführen oder den User bzw. Melder unterstützen dies selbst zu tun. Die einzelnen Schritte müssen dokumentiert werden.
Aktivitätsspezifische Regeln
- wenn nötig einen RFC stellen und auf das Ergebnis des Changes warten
ID des Changes bzw. der Changes in „ausgelöste Changes“ dokumentieren - oder die Instandsetzung wird selbst durchgeführt
- oder der Melder bzw. Anwender wird bei der Instandsetzung unterstützt
- die interne und externe Lösungsbeschreibung wird gefüllt
- gegebenenfalls Übergangslösung dokumentieren
- gegebenenfalls auf bekannte Fehler und Probleme verlinken
- gegebenenfalls Dokumente anhängen
- gegebenenfalls Anmerkungen dokumentieren
Incident Testing
Wenn ein Incident wieder instandgesetzt ist, muss die Funktionalität des Service geprüft werden. Die folgenden Aktionen müssen in diesem Test durchgeführt werden:
- Ausführen von in der Servicebeschreibung definierten Testprozeduren
- Testen, ob alle Incident-Symptome eliminiert sind
Die Ergebnisse müssen im Record dokumentiert werden. Wenn das Change Management in die Instandsetzung involviert war und ein Test bereits durchgeführt wurde, dann kann ein weiterer Test wegfallen. Falls möglich, sollte der Tester eine andere Person sein als die, die die Instandsetzung getestet hat.
Aktivitätsspezifische Regeln
- Durchführen des Tests
- Dokumentation des Ergebnisses
- falls der Test nicht erfolgreich ist, zurück zur Untersuchung
Incident Abschluss (Closure)
Wenn ein Incident als “erfolgreich getested” angezeigt wird, muss der Benutzer bzw. informiert werden. Falls benötigt, muss dieser der erfolgreichen Instandsetzung zustimmen. Falls er die Bestätigung der erfolgreichen Instandsetzung verweigert, wird das Ticket zum Initial Support zurückgesendet. Wenn ein Alarm (event) den Incident ausgelöst hat, ist keine Bestätigung erforderlich. Die Lösung muss dokumentiert werden. Dies ist nötig, um eine Wissensdatenbank (Knowledge Database) zu erstellen. Die letzte Aufgabe ist es dann, das Incident Ticket abzuschließen.
Aktivitätsspezifische Regeln
- Der Incident Bearbeiter wird auf den Inicident Verantwortlichen gesetzt.
- Der Bearbeiter informiert den Benutzer und Antragsteller und wartet gegebenenfalls seine Zustimmung ab.
- Falls die Zustimmung verweigert wird, ist das Ticket erneut in die Untersuchung zu schicken.
- Ansonsten werden alle Einträge im Record überprüft und korrigiert.
- Gegebenenfalls werden weitere Dokumente angehängt.
- Die Abschlussanmerkung wird eingetragen.
- Das Ticket wird geschlossen.