Incident Management
Description/Summary
Incident Management provides the process, tools and concept for the fast recovery of service quality in a defined service. It deals with service issues, and with all other service and user requests recorded by a service desk. It also monitors the completion of requests by the service desk or by all other service units. Finally, Incident Management has the task of informing the service requester on the status of a service request.
Objectives
The purpose of Incident Management is to recover normal (i.e. agreed) service operation, as quickly as possible, after an incident has been detected/recorded.
Incident Management contributes to an integrated Service Management approach by achieving the following goals:
- Every incident and all required data is recorded.
- Every incident runs through a set of standardized activities and procedures, in order to ensure effective and efficient processing.
- Every incident is categorized and prioritized regarding its (potential) impact and urgency, in order to schedule its resolution in a business-oriented way.
- Functional and hierarchical escalation procedures are in place in order to ensure that each incident is investigated by qualified members of staff, either by internal or external experts.
- Well-defined functional escalation levels ensures that all incidents are handled in a cost-efficient way and that experts are relieved from non-expert diagnosis and resolution activities.
Roles and Functions
Incident Management Specific Roles
Static Process Roles
- Process Owner: Initiator of the process, responsible for defining its strategic goals and allocating all required resources
- Process Manager (Incident Manager): Manager of the entire process, responsible for its effectiveness and efficiency
Dynamic Process Roles
- Incident Agent: see IT Service Management Principles Ticket, Ticket Owner and Ticket Agent for details
- Incident Owner: see IT Service Management Principles Ticket, Ticket Owner and Ticket Agent for details
Service Specific Roles
- First Level Support – in general this is equivalent to the function of the Service Desk: A person working in the Service Desk function; acts as a Ticket Agent and Ticket Owner
- Expert / Service Specialist
- Second Level Support member of staff: A person working in an internal IT department and providing expert qualities in one or more specific areas; acts as a ticket agent (see below)
- Third/n-th Level Support member of staff: A person working in an internal IT department, or for an external supplier, and providing specialist qualities in one or more specific areas; acts as a ticket agent (see below)
Customer Specific Roles
- User: Person who is affected by the Incident
- Caller: The person who reports the Incident. This may be the same as the „User“
- Service Desk
Information Artifacts
This section outlines information/data required or recorded by the process. In general, a process record (here: the incident record) contains all information needed to execute this process and also represents the current progress of a process. Additional information items (artifacts) typically can be realized by considering the information from one or more (up to all) process records. This can be done by either filtering, merging, correlating or interpreting information from these records; sometimes this can also be done in the context of information and data from other sources.
The Incident Record
The Incident Record holds any management-relevant information for a specific incident. On creation, it is based on (filled with) the information provided by the user or system/tool reporting the new incident.
The following attributes must be considered for an Incident Record:
- Unique Identifier
- Incident Owner
- Incident Agent
- Caller
- User
- Customer
- Status of the Incident (Record)
- Description of the Incident Symptoms
- Service Level Agreement (SLA defined urgency)
- Current Assessed Impact of the Incident
- Priority (according to urgency and impact)
- Services Affected by the Incident
- Related Configuration Item
- General check list result
- Specific check list result
- Investigation results
- Problem(s) or Error(s) Related to the Incident
- Applicable Workaround(s) (link to workaround database)
- Request(s) for change(s) triggered
- Resolution/Recovery describtion
- Resolution date and time
- Testing result
- Result of Service Recovery Confirmation Request
- Closure date and time
- Additional Remarks
Key Concepts
Major Incident Handling
The incident of priority „1“ is a Major Incident. In order to accelerate process execution in such a case, the following special procedures for the handling of Major Incidents are proposed. The Service Owner takes over the Ownership of the Ticket from the Service Desk. He is now accountable for the Incident. See Ticket, Ticket Owner and Ticket AgentTicket Owner for detailed information.
Priority
Priority is a control parameter in the process and supports the Incident Management Staff in the efficient management of resources (staff, capacity, time etc.). Services with higher service levels will have a higher priority („1“ is the highest priority). Priority is defined by combining impact and urgency:
- Impact – this describes the situation of an incident and is defined by the following factors:
- Number of affected users
- Percentage of affected users
- Urgency – this defines the priority of incidents when the impact of those incidents are the same.
Information Duty
First level support / line support has the duty to inform the user about the status of an incident especially, when the incident cannot be fixed immediately. The user should know about the status of an incident, between the status „work on incident started“ and „work on incident stopped“. If user and caller are different persons, both persons should be informed on status. Regular status information helps to avoid escalations because the user is informed and know that his request is taken care of. A information can be triggered by event and by time schedules.
Hierarchical Escalation
Incidents can be escalated hierarchically when the process can not be fulfilled in „regular“ way. This case occurs when:
- available resources are not sufficient
- agreements in ULA/ UC contracts can not be fulfilled
- service level can not be fulfilled
Escalation can be performed at each point of an incident’s life cycle. See Hierarchical Escalation for detailed information
Incident Controls
| status | description |
|---|---|
| new | A new incident is identified or reported. |
| registered | A new incident is registered if all the necessary Information has been stored in the Incident Record. |
| service selected | The affected service is identified. |
| classified | All important control factors have been determined, e.g.priority of the affected service respectively the Service Level Agreement. Also the type of procedure is defined. |
| forwarded | The record has been forwarded. |
| assigned | If an incident could not be resolved by the 1st Level, it has to be forwarded/functionally escalated to the expert team. |
| solution found | An incident where the solution is found. |
| recovered | An incident, which is resolved (with or without Change Management). |
| failed | An incident, with formerly status recovered, which has not successfully passed the required tests or the user has the solution rejected is failed. |
| solved | An incident has passed the required test. |
| confirmed | The user has confirmed the solution of an incident and that the request has been handled successfully. |
| aborted | An incident which did not completely pass the lifecycle. |
| end | The final status of a completed incident. |
Process
High Level Process Flow Chart
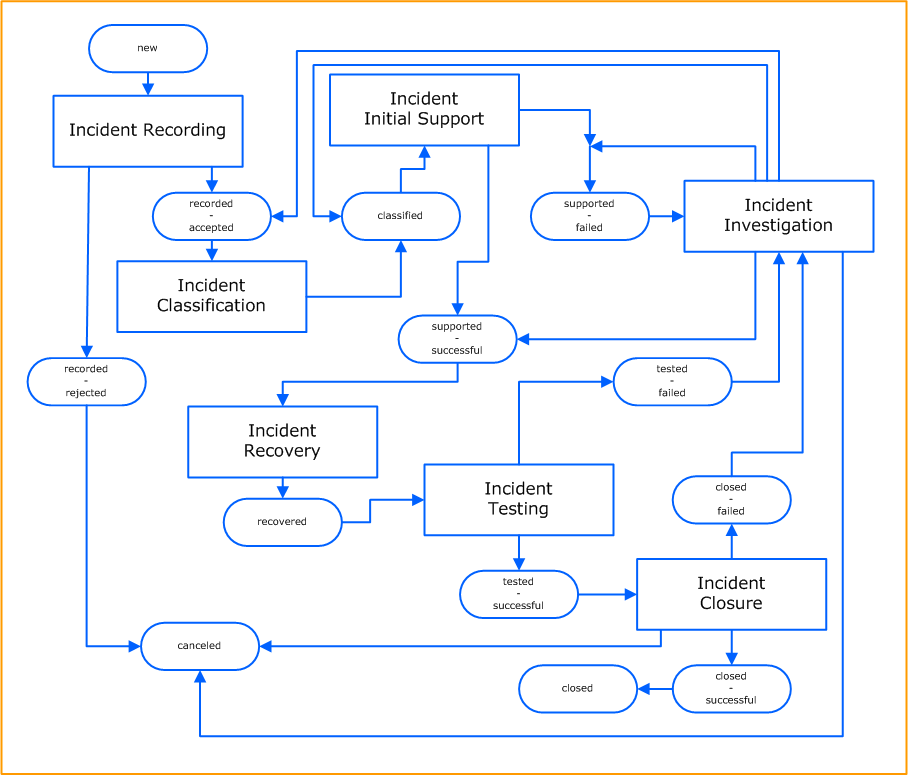
Critical Success Factors
- Incident overload and backlog
- Reliable data from the Configuration Management
- Extensive “Knowledge Database” which includes Problem Descriptions, Known Errors, Resolutions and Workarounds
- Automated Ticket Tracking Systems
- Lack of Service Level Agreements
- Users and IT staff bypassing Incident Management process
Performance Indicators (KPI)
- Total Number of Incidents
- Average Resolution Time
- Percentage of Incidents resolved by first-line support (without routing)
- Number(or percentage) of Incidents with initial incorrect classification
- Average Support Costs per Incident
- Number(or percentage) of Incidents Routed Incorrectly
These can be monitored using the following measures: per priority, per service, per user, per customer, per location, etc
Process Trigger
Event Triggers
- Any reported incident triggers the incident management process, which may be reported using one of the following methods:
- User calls, mails, web form
- Event management monitoring tools
- Technical staff calls or mails
Time Triggers
- None (Incident Management is typically event-triggered)
Process Specific Rules
- for each reported Incident a new Incident Record with an unique identifier is created.
- a change of the Incident Owner/Agent is only allowed, if the new Incident Owner/Agent agrees.
- preferably, a person rather than a group should be the Incident Owner/Agent.
- inform user/caller on the status of ticket handling after each activity
Process Activities
Incident Recording

All upcoming incidents are be logged; a ticket in a trouble ticket system is created for each incident. In order to facilitate incident ownership, tracking and escalation, a ticket owner is defined according to the roles indicated above.
Activity Specific Rules:
- Default Incident Owner is set to Service Desk
- in case an Incident was reported by a caller; the member of Service Desk recording the incident is, from this point in time on, the Incident Owner.
- set Incident Agent = Incident Owner
- set User and Caller
- set Customer
- „Default Incident Priority“ is set to 1
- „Default Incident Status“ is set to new
- document the Incident symptoms in the Incident Describtion
- if the user/customer is valid and is allowed to trigger an incident for this service, then go to control activity „recorded – accepted“
- otherwise go to „recorded – rejected“
- set Configuration Item to „-„
Incident Classification

This classification aims at recording the class/type of the incident and provides essential information for subsequent prioritization. This activity is crucial for the success of the following sub processes
In a first step, the affected service and the adequate SLAs are classified (set). Then the priority can be defined based on SLAs for a certain service. Other control factors will have to be set as well.
Activity Specific Rules:
- Service is set to the affected Service or Sub Service
- Service Level Agreement is set to the relevant SLA for the selected user (customer) and service
- Impact is set by a consideration of the Incident Symptoms Description
- Priority is set according to urgency and impact, as described in the Service Level Agreement
- Other control factors are set
- Go to control activity „classified“
Incident Initial Support

This activity checks if an incident has already been reported or if a solution exists for the incident (known incidents).
Classified incidents are checked according to the following general checklist:
- are there any open incidents of same service reported?
- are there any closed incidents of same service documented?
- are there any open problems of same service reported?
- are any workarounds known?
- are there any recently implemented changes addressing same service?
If one of those questions can be answered with „YES“, this may decrease the handling time needed for an incident’s solution. If none of questions above can be answered, a service specific check list need to be used. This service specific check list is provided in the service description.
Depending on the quality of the investigation, less incidents will need to be escalated to the Service Expert Support Level.
Following the result of the Incident Initial Support, an incident should be assigned to the owner of similar incidents. This should avoid that two different owners handling the similar incident. Incidents occurring simultaneously will in most cases have the same reason and therefore can be consolidated. Good documentation about solutions of solved incidents can help to decrease handling time of new incidents. This correlation of incidents to problems is only possible if a Problem Management Process exists. Known workarounds of incidents can also improve the handling times of new incidents.
Activity Specific Rules:
- execute general checklist
- execute service specific checklist
- describe the result of the general checklist
- describe the result of the service specific checklist
- describe the solution
- if a solution is found within this activity then go to control activity „supported – successful“
otherwise
- set the Incident Agent to Service Expert by functional escalation
- go to control activity „support – failed“
Incident Investigation
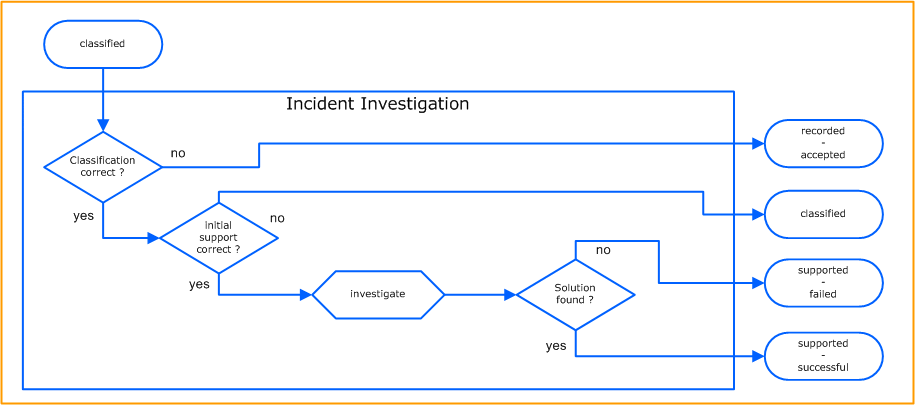
Incident Investigation is the most complex activity of the Incident Management Process. The incident is investigated by using available information on the incident symptoms with the aim of achieving a quick resolution of the incident and a restoration of the disrupted service(s). This available information is provided by the general and specific checklists. Additional information can be: affected services, CIs, users, related incidents, errors, information out of the CMDB, and technical expert knowledge.
The first action in this activity is to check whether the classification, especially the determination of the Service, has been completed correctly. If not, the incident is returned to the Service Desk for reclassification.
If the classification was correct, then the results of the general and service specific checklist are reviewed. If the initial support was wrong, then the incident is returned to the Service Desk to complete.
If both decisions are passed successfully, then the 2nd level support (or 3rd) starts its investigation. If a solution is found they then execute the recovery activity, then they can pass the Incident Ticket back to the Service Desk.
If no solution is found, it can be functionally escalated to a Specialist.
Activity Specific Rules:
- if classification was NOT correct
- set Incident Agent to either Service Desk or the former Incident Agent to reclassify
- go to control activity „recorded - accepted“
- if initial support was NOT correct
- set Incident Agent to either Service Desk or the former Incident Agent to re-execute initial support
- go to control activity „classified“
- if no solution was found
- set Service Agent to an appropriate Service Specialist
- inform the Service Owner
- go to control activity „supported - failed“
- otherwise
- if the next activities (recovery, testing, …) are to executed by Service Desk
- set Service Agent to Service Desk
- go to control activity „supported - successful“
- if the next activities (recovery, testing, …) are to executed by Service Desk
Incident Recovery
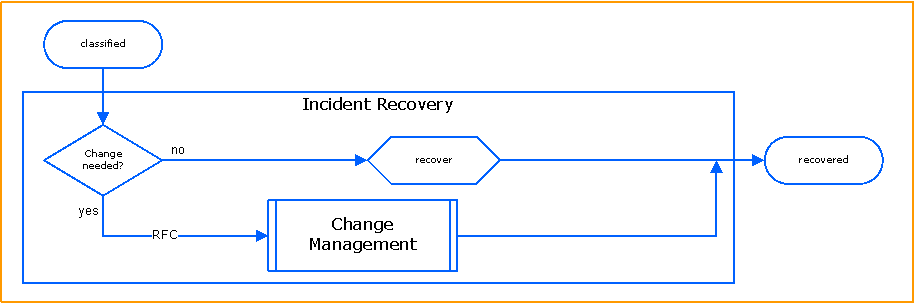
Once a solution has been found, then different recovery options are possible. If a Change is needed, then the Change Management Process has to be triggered. Otherwise the Incident Agent can either perform the recovery or can guide the user/caller to do so. The individual steps must be documented.
Activity Specific Rules:
- if a change is needed to recover the Incident Change Management has to be triggered
Otherwise
- the Incident Agent has to perform the tasks to recover the service
or
- the Incident Agent has to guide the user/caller to perform the tasks:
- document recovery
- go to the control activity recovered.
Incident Testing

If a incident is recovered, the functionality of the live-system needs to be tested. The following actions need to be performed during this testing:
- see the Service Description for Specific Testing Procedures
- testing (test especially if all incident Symptoms have disappeared)
- approval of the implementation
The test result must be documented in the Incident Record. If Change Management was involved in the recovery and a test was already performed, then this testing can be skipped. If possible, this tester should be different from the Person who tested the recovery.
Activity Specific Rules:
- set Incident Agent to Service Desk
- execute test
- record test result
- if test was successful, go to control activity „tested – successful“
otherwise
- set Incident Agent to a Service Expert
- go to control activity „tested – failed“
Incident Closure
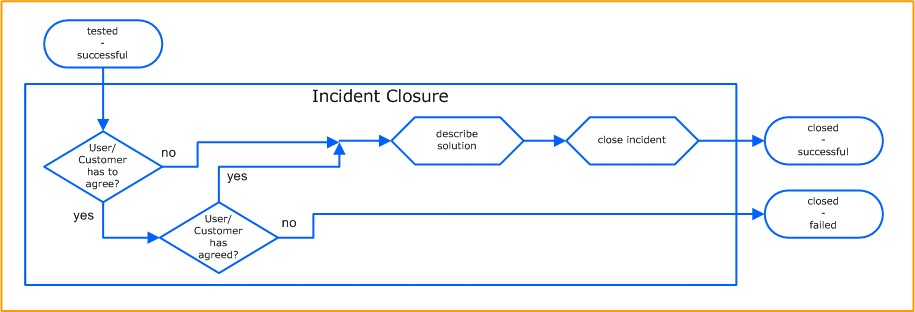
When an incident is reported as tested successful, the user has to be informed. An answer is required from the user (caller/Customer) to confirm or deny that there has been a successful recovery to normal service operation. If an alert (event) triggered the Incident, then no conformation is needed.
The solution must then be documented. This is necessary in order to build a Knowledge Database. The final task to close the Incident Ticket must then be performed. If the user (caller/Customer) refuses to confirm this is successful, then the Ticket has to be send back to Initial Support.
Activity Specific Rules:
- if the user confirms testing is successful, set the Incident Agent to the user
- when the user refuses to confirm, go to control activity „closed – failed“
otherwise
- set Incident Agent to Service Desk
- document the solution
- close the Incident
- go to control activity „closed – successful“