Problem Management
Beschreibung / Zusammenfassung
Das Ziel des Problem Management ist die permanente Lösung wiederkehrender Störungen (Incidents). Dieses Ziel wird durch reaktive und präventive Maßnahmen erreicht:
- Reaktives Problem Management analysiert die Gründe von Incidents und entwickelt Vorschläge zur Unterbindung weiterer Incidents aufgrund dieser Gründe.
- Präventives Problem Management versucht Incidents im Vorfeld zu verhindern bzw. die Auswirkungen von Incidents zu minimieren. Dies wird erreicht indem IT-Service auf Schwachstellen geprüft und diese Schwachstellen beseitigt werden.
Weitere Leistungen des Problem Managements:
- Kontinuierlicher Verbesserungsprozess in Bezug auf IT Infrastruktur durch das Verhindern von Incidents
- Strukturelle Fehler werden erkannt, erfasst, verfolgt und gelöst
- Entwicklung einer „Knowledge Database”
- Generieren von Change Requests (RFC) zur Verbesserung der IT Infrastruktur
Das Problem Management muss in enger Zusammenarbeit mit dem Change Management stehen.
Zielsetzung
Der Zweck des Problem Management besteht darin, standardisierte Prozeduren einzuführen, welche bestehende IT Prozesse analysieren und die Erfüllbarkeit von vereinbarten SLAs sicherstellen sollen. Ebenso werden Incidents analysiert um zu verhindern, dass diese zu Major Incidents heranwachsen können.
Das Problem Management trägt zu einem ganzheitlichen Service Management Ansatz bei indem es
- die Grundursachen von Problemen identifiziert
- und dadurch Incidents verhindert
Rollen & Funktionen
Spezifische Rollen im Problem
Rollen im Grundprozess
Für Details, siehe Abschnitt Problem Management, Service Management Rollen x Personen Problem Management Prozessverantwortlicher Initiator des Prozesses, verantwortlich für die Definition des strategischen Prozess Ziele und für die Einteilung der notwendigen Ressourcen. Für eine detaillierte Beschreibung der Aktivitäten siehe: Continual Process Improvement Management.
Problem Management Prozessmanager (Problem Manager)
Manager des Gesamtprozesses, verantwortlich für Effektivität und Effizienz des Prozesses. Teamleiter des „Problem Management Team“. Für eine detaillierte Beschreibung der Aktivitäten siehe Continual Process Improvement Management .
Problem Management Team
Team der Mitarbeiter des Problem Management Prozesses.
Senior Management
Senior Management des IT Providers
Rollen im Dynamischen Prozess
Die folgenden Rollen werden dynamisch während des Problem Management Prozesses ins Leben gerufen. Für eine detaillierte Beschreibung sehen Sie bitte unter „Prozessspezifische Regeln“ oder „Aktivitätsspezifische Regeln“ nach.
Problem-Besitzer
Ein Attribut des Datensatzes beinhaltet die Rolle/Funktion, die gegenwärtig für das Problem verantwortlich ist (Achtung: NICHT für den Problem Management Prozess). Der Problem-Besitzer kann mittels hierarchischer Eskalation geändert werden.
Problem Agent
Ein Attribut des Datensatzes beinhaltet die Rolle/Funktion die gegenwärtig für eine Aktivität oder die Aufgaben innerhalb der Aktivität verantwortlichist. Der Problem Agent kann mittels funktionaler Eskalation geändert werden, falls dies laut den Regeln genehmigt ist.
Diagnoseteam
Team der Mitarbeiter des Problem Management, die nach den Grundursachen von Problemen suchen.
Lösungsteam
Team der Mitarbeiter des Problem Management, die für die Beseitigung der Grundursachen von bekannten Störungen zuständig sind. Das Lösungsteam wird aus Mitarbeitern des Diagnoseteams zusammengestellt.
Service-spezifische Rollen
Service-spezifische Rollen sind in der Leistungsbeschreibung definiert. Die Leistungsbeschreibung und die Beschreibung der service-spezifischen Rollen werden vom Service Portfolio Management geliefert. Beispiel: Leistungsbeschreibung Service Spezialist
Service-Spezialisten helfen dem / im
- Problem Agenten
- Diagnoseteam
- Lösungsteam
Service-Besitzer
Person die für den Service laut Leistungsbeschreibung verantwortlich ist.
Kundenspezifische Rollen
Kundenspezifische Rollen sind im Service Level Agreement (SLA) beschrieben. Die SLA bezüglich der kundenspezifischen Rollen werden vom Service Agreement Management gepflegt.
Kunde(n)
Kunden der betroffenen Service mit gültigem SLA. Beispiel: Service Level Agreement
Informations-Artefakte
Dieser Abschnitt beschreibt welche Informationen/Daten bei dem Prozess benötigt bzw. gespeichert werden. Generell beschreibt der Prozessbericht (hier der Problembericht) den gegenwärtigen Fortschritt im Prozess und beinhaltet alle Informationen, die mit der Durchführung des Prozesses in Zusammenhang stehen. Zusätzliche Informationspunkte (sogenannte Artefakte) können in der Regel aus Informationen verschiedener Prozessprotokolle zusammengetragen werden (durch Filtern, Zusammenfassung, Ergänzung, Auslegung dieser Informationen).
Bericht Trendanalyse
- Trendanalyse Design ID
- Trendanalyse Anforderer
- Trendanalyse Beschreibung
- Trendanalyse Design-Agent
- Trendanalyse Agent
- Trendanalyse Prüfungs-Agent
- Trendanalyse Service Spezialist
- Trendanalyse Service: Betrachteter Service
- Trendanalyse Base Daten
- Trendanalyse relevante Incidents IDs und Problem IDs
Problembericht
Der Problembericht (Problem Ticket) enthält alle managementrelevanten Informationen und die Historie eines bestimmten Problems.
- Eindeutiger Identifikator: Problem ID
- Problemmelder: Name der Person die den Change ausgelöst hat
- Problembesitzer: Siehe Abschnitt „Rollen“
- Prozessvorgang: Eindeutiger Identifikator des Prozessvorganges der den Problem Management Prozess ausgelöst hat. Dies kann auch eine Probleminstanz sein.
- Status : Status des Problems. Wird festgelegt wenn eine Kontrollaktivität durchgeführt wird.
- Service : Services die von dem Problem betroffen sind
- Kunden : Kunden die von dem Problem betroffen sind
- Problembeschreibung: Beschreibung des Problems
- Diagnoseteam: Siehe Abschnitt „Rollen“
- Geplante Startzeit / -datum der Diagnose-Aktivität
- Lösungsteam: Siehe Abschnitt „Rollen“
- Geplante Startzeit / -datum der Lösungs-Aktivität
Hauptbegriffe
Problem & Bekannte Störung
Ein Problem ist ein unbekannter Grund für einen oder mehrere (potentielle) Störungen (Incidents). Im Falle einer Bekannten Störung ist zwar der Grund der Störung bekannt – aber in der Regel nicht die Lösung
Trendanalyse
In der Trendanalyse werden Berichte analysiert die auf Störfaktoren in anderen Prozessen hinweisen. Diese Berichte stammen hauptsächlich aus dem Incident Management, Availability Management und dem Capacity Management. Wenn Störfaktoren identifiziert werden, sollte eine ausführliche Analyse des Themas durchgeführt werden. Beispiel: Aufgrund einer Incident Statistik wird offensichtlich, dass die Anzahl der Incidents in Zusammenhang mit einem Email System in einem bestimmten Zeitintervall ungewöhnlich hoch ausfällt. Eine Analyse wird bereitgestellt. Die Ergebnisse der Analyse können sein:
- Die Anzahl der User hat in gleichem Maße zugenommen wie die Anzahl der Incidents. Da die Anzahl der Incidents proportional ist zur Anzahl der User, sind keine weiteren Aktionen notwendig.
- Einer der E-Mail Server hat nicht die vereinbarte Verfügbarkeit erreicht. Der Anstieg der Incidents ist auf diesen E-Mail Server zurückzuführen. Gründe hierfür könnte z. B. veraltete Hardware sein. Gemeinsam mit dem Availability Management werden die weiteren Schritte zur Lösung des Problems erarbeitet.
Workaround (Temporäre Lösung)
Wenn das Problem nicht umgehend gelöst werden kann bietet das Problem Management dem Incident Management eine temporäre Zwischenlösung an. Eine temporäte Lösung darf auch unmittelbar vom Incident Management vorgeschlagen werden und wird dann vom Problem Management als sogenannter Workaround dokumentiert.
Hierarchische Eskalation
Wenn der Problem Management Prozess nicht nach dem definierten Prozess durchgeführt werden kann, wird eine hierarchischen Eskalation ausgelöst. Die erste Eskalationsstufe ist der „Problem Manager“. Zu jedem Zeitpunkt des Lebenszyklus eines Problems kann ein Ticket zum Problem Manager eskaliert werden.
Problem-Steuergrößen
Status – Definition
- Neu – ein mögliches Problem wurde identifiziert
- Erstellt – das Problem wurde beschrieben (Übersicht erstellt)
- Registriert – das Problem wurde im Detail beschrieben und Kategorisiert
- Kategorisiert – Alle Steuerdatenfeder des Problems wurden gefüllt
- Festgestellt – Die Ursache des Problems wurde erkannt und ein „Bekannter Fehler“ wurde bestimmt
- Fehler registriert – Alle Steuerdatenfeder des Bekannten Fehlers wurden gefüllt
- Lösung gefunden – Aus den Lösungsvorschlägen wurde eine Lösung ausgewählt
- Wiederhergestellt – Die Lösung des Problems wurde angewandt
- Fehlgeschlagen – Die Lösung hat den PIR (Post Implementation Review) NICHT bestanden und ist somit nicht erfolgreich
- Gelöst – Die Lösung hat den PIR bestanden
- Abgebrochen – Analyse und Lösung des Problems wurde abgebrochen. Der Problembericht kann nicht den gesamten Lebenszyklus des Problems dokumentieren
- Ende – Die Nachforschungen und der Lösungsprozess wurden endgültig abgeschlossen
Prozess
Kritische Erfolgsfaktoren
- Incident Management und Problem Management müssen eng zusammen arbeiten, brauchen aber eindeutig abgegrenzte Verantwortungsbereiche
- Zugriff auf gut ausgebildete, erfahrene Techniker der IT Einheiten
- Zugriff auf interne und externe Datenbanken zur Vermeidung von Incidents
- Sinnvolle und durchgängige Trend Analysen
Trend Analyse von Problemen
Die Trend Analyse nutzt Informationen von Störungen und Problemen und versucht Muster – oder Trends – zu erkennen welche wiederum genutzt werden können um neue mögliche Störungen und Probleme im laufenden Betrieb vorherzusagen. Häufig kommen hier statistische Methoden zum Einsatz.
High Level Process Flow Chart
Diese Grafik zeigt den Problem Management Trend Analyse Prozess sowie das Status Modell wie im Problembericht beschrieben.

Key Performance Indicators (KPI)
- Verlässlichkeit der Trend Analyse
- Transparenz bezüglich eingesetzter Tools und Methoden
Prozessauslöser
Eventauslöser
Der Prozess wird nicht durch ein Ereignis ausgelöst.
Zeitlicher Auslöser
Die Trend Analyse wird innerhalb von definierten Zeitintervallen ausgeführt.
Prozessspezifische Regeln
- Alle Änderungen an Trend Analyse Aktivitäten müssen dokumentiert werden
- Alle Änderungen an Trend Analyse Aktivitäten müssen kommuniziert werden
Anmerkung: Für die verschiedenen Regel-Typen siehe: Regeln.
Prozess Aktivitäten
Design der Trendanalyse
Durch diese Aktivität wird das Design der Trendanalyse des Problem Management bewerkstelligt. Zuerst wird festgelegt, welche Daten überwacht werden müssen. Diese Analyse wird auf Grund der Berichte vom Report Management erstellt. Verschiedenste Trendanalyse-Tätigkeiten sind möglich. Die geeignetste der folgenden Methode muss gewählt werden:
- Least-squares method
- Random data method
- Trend plus noise analysis
- R-squared analysis
- Correlation analysis
Die Aktivität besteht aus den folgenden Schritten:
- Definition der Probleme und Störungen die in Betracht gezogen werden
- Sammlung und Analyse der verschiedenen Berichte für die Bestimmung der oben genannten Werte
- Definition der Werte für die Trendanalyse aufgrund der Berichtanalyse
- Anweisung an das Report Management, die relevanten Daten in entsprechenden Berichten zusammenzutragen
- Definition der Schwellenwerte für die Berichte
- Definition der Gegenmaßnahmen für den Fall dass Schwellenwerte überschritten werden
Aktivitätsspezifische Regeln
- Anforderer der Analyse wird gesetzt auf die Person die die Analyse angestoßen hat
- Sponsor der Analyse wird gesetzt auf die Person die die Analyse angestoßen hat, sofern kein anderer Sponsor bekannt ist
- Besitzer der Analyse ist für die Trendanalyse verantwortlich
- Agent der Analyse ist der Besitzer der Analyse
- Beschreibung der Analyse muss eine aussagekräftige Beschreibung des Problems enthalten
- Betroffener Service muss mindestens einen Service beschreibenDurchführung der Trendanalyse
Durchführung der Trendanalyse
Mit dieser Aktivität wird die beschriebene Analyse unter Gebrauch der vom Report Management generierten Berichte durchgeführt. Falls definierte Schwellenwerte überschritten wurden werden Gegenmaßnahmen eingeleitet.
Aktivitätsspezifische Regeln
- Anforderer der Analyse wird gesetzt auf den Service Spezialisten
- Berichte vom Reporting Management werden kontrolliert
- Berichte vom Reporting Management werden analysiert
- Gegenmaßnahmen werden festgelegt
- Falls die Analyse verändert werden muss wird zum Analysedesign zurückgekehrt
Überprüfung der Trendanalyse
In dieser Aktivität wird die Trendanalyse auditiert. . Falls definierte Schwellenwerte überschritten wurden werden vom Problem Management Gegenmaßnahmen eingeleitet. Das Problem Management wird mittels Ticket informiert. Diese Aktivität wird gemeinsam vom Service Besitzer und dem Service Spezialisten durchgeführt.
Aktivitätsspezifische Regeln
- Berichte vom Reporting Management werden kontrolliert
- Berichte vom Reporting Management werden analysiert
- Gegenmaßnahmen werden festgelegt
- Falls definierte Schwellenwerte überschritten wurden wird ein Problem Ticket eröffnet
- Falls die Analyse verändert werden muss wird zum Analysedesign zurückgekehrt
Abwicklung von Problemen
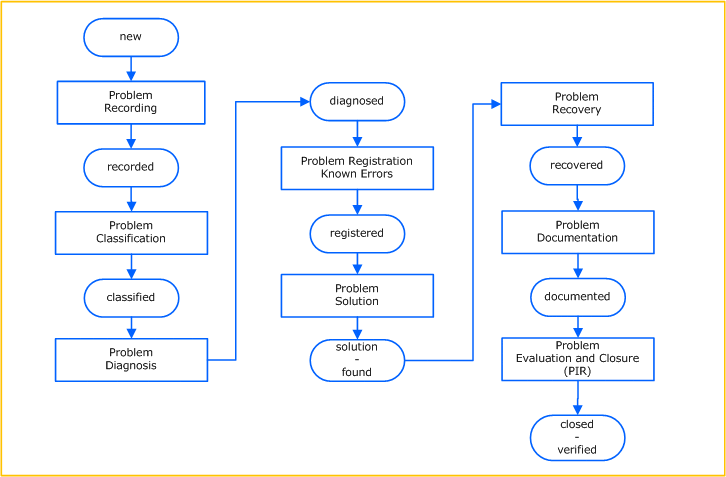
High Level Process Flow Chart
Diese Grafik zeigt den Problem Management Prozess und die darin enthaltenen Aktivitäten sowie das Status Modell wie im Problembericht beschrieben.
Key Performance Indicators (KPI)
Definition of Performance Indicators
Offenes Problem
Ein offenes Problem kann folgenden Status haben:
- Neu
- Eröffnet/Offen
- Registriert
- Kategorisiert
Geschlossenes Problem
Alle Probleme die NICHT offen sind
Bekannte Störung
Eine Bekannte Störung kann folgenden Status haben:
- Erkannt
- Fehler registriert
- Lösung gefunden
- Wiederhergestellt
- Fehlgeschlagen
Dauer der Problemuntersuchung
- Zeitstempel Erkannt – Zeitstempel Neu
Dauer der Lösungsdefinition
- Zeitstempel Gelöst – Zeitstempel Erkannt
Definitionen der KPIs
Alle Indikatoren werden getrennt je Service, Kunde und Priorität analysiert. Der Problem Manager ist die verantwortliche Person. Typische Einstellungen für Analyse-Zeitintervalle sind: • 1 Monat • 1 Quartal • 1 Jahr
Key Performance Indicators KPI
- OP = („Anzahl offener Tickets im Zeitintervall“/ „Anzahl offener Tickets im vorherigen Zeitintervall“) – 1
- CP = („Anzahl geschlossener Tickets im Zeitintervall“/ „Anzahl geschlossener Tickets im vorherigen Zeitintervall“) – 1
- KE = („Anzahl Bekannter Fehler im Zeitintervall“/ „Anzahl Bekannter Fehler im vorherigen Zeitintervall“) – 1
- UE = („Anzahl unbekannter Fehler im Zeitintervall“/ „Anzahl unbekannter Fehler im vorherigen Zeitintervall“) – 1
Prozessauslöser
Ereignisauslöser
Die Problemanalyse wird ausgelöst durch:
- den Incident Management Prozess
- den Problem Management Prozess selbst, wenn eine Analyse des Problem Management notwendig ist
Für weitere Informationen siehe: Prozess-Schnittstellen Übersicht
Zeitlicher Auslöser
Keine (der Problem Management Prozess wird immer durch ein Ereignis ausgelöst)
Prozessspezifische Regeln
- Jedes Problem löst das Anlegen eines neuen Problemberichts aus.
- Der Problem Agent ist dafür verantwortlich dass jede Aktivität im Problembericht dokumentiert wird.
- Der Problembesitzer muss den Problem Agent steuern.
- Der Problembesitzer und der Problem Agent dürfen ihre Aufgaben nur übergeben wenn die empfangende Person oder Gruppe zustimmt.
- Die neuen Problembesitzer und Problem Agenten müssen bei den entsprechenden Attributen des Problemberichts eingetragen werden.
- Der Problembesitzer und der Problem Agent sollen nach Möglichkeit eine Person sein und keine Gruppe.
- Weitere Informationen über Service Beschreibung und zu Service Level Agreement erhalten Sie hier: Servicespezifische bzw. Kundenspezifische Regeln
Anmerkung: Für die verschiedenen Regel-Typen siehe: Regeln.
Prozessaktivitäten
Problem-Berichterstattung
Das Problem wird dokumentiert indem der Problembericht ausgefüllt wird. Der Problembericht wird auf Vollständigkeit und formelle Fehlerfreiheit überprüft. D.H. dass geprüft wird ob alle Pflichtangaben vom Antragsteller erteilt und eingetragen wurden. Falls dies nicht der Fall ist oder falls der Antragsteller nichtautorisiert ist, Problemberichte aufzugeben kann das Problem zurückgewiesen werden.
Aktivitätsspezifische Regeln
- Problem Melder wird gesetzt auf die Person die das Problem angestoßen hat.
- Problem Sponsor wird gesetzt auf die Person die das Problem angestoßen hat, sofern kein anderer Sponsor bekannt ist
- Problem Agent wird gesetzt auf Problem Management Team, sofern keine andere Person als Problem Agent gefunden werden kann
- Problem Besitzer wird gesetzt auf Problem Management Team, sofern keine andere Person als Problem Besitzer gefunden werden kann
- Problembeschreibung muss eine aussagekräftige Beschreibung des Problems enthalten
- Problem Priority wird gesetzt auf „3 (Mittel)“ sofern keine andere Priorität bekannt ist.
- Betroffener Service – Hier muss mindestens ein Service definiert sein.
Problem-Kategorisierung
Durch die Problem-Kategorisierung wird dem Problem eine Steuergröße gegeben. Die Kategorisierung hilft auch bei fachlichen Entscheidungen in der Vorbereitungsphase. Bei der Klassifizierung werden Priorität und Kategorie bestimmt. Die Priorität richtet sich meist nach der Dringlichkeit und die Auswirkungen der zugehörigen Incidents und Probleme und gibt somit Vorgaben zur Priorisierung der Problemimplementierung. Die Kategorie ist unter anderem von dem Risiko des Problems abhängig, vor allem in Bezug auf IT Serviceabläufe, potentielle Störungen und Qualitätsminderung. Ein erfasstes und angenommenes Problem muss zuerst kategorisiert werden und wird dann je nach Kategorie abgewickelt. Das Diagnoseteam wird festgelegt und Startzeit / -datum für die Aktivität „Problem Diagnosis“ werden bestimmt. Das Diagnoseteam muss ein breites Spektrum an Fähigkeiten(Skills) aufweisen.
Ein Standard-Problem („Kategorie 0“) gilt als vorautorisiert und kann sofort laut behandelt werden. Für ein geringfügiges/Minor Problem („Kategorie 1“) muss eine Risikoanalyse und ein Proof-of-Concept durchgeführt werden, wobei hier die Adeliger Prozesse unterstützend mitwirken. Basierend auf den Ergebnissen von Risikoanalyse und Proof-of-Concept kann die Kategorie eines Problems auch nachträglich aktualisiert werden. Andernfalls wird die bestehende Kategorie bestätigt.
Sofern die Problemkategorie geändert werden soll wird der Prozess Problem Kategorisierung neu gestartet und das Problem wird anschließend gemäß der neuen Kategorie abgewickelt.
Die folgende Aktivität unterscheidet sich je nachdem ob die Kategorie bestätigt wurde oder aktualisiert werden soll.
Aktivitätsspezifische Regeln
- Problem Besitzer wird gesetzt auf „Service Besitzer“ oder „Problem Manager“ wenn kein Service definiert ist.
- Problem Agent wird gesetzt auf Problem Management Mitarbeiter.
- Das Ergebnis der „Risiko Analyse“ und des „Proof of Concept“ muss im Problembericht dokumentiert werden
- Die „Problem Priorität“ wird anhand des Ergebnisses definiert.
- Die „Problem Kategorie“ wird anhand des in der Risiko Analyse bestimmten Risikos definiert.
- Das Diagnosis Team ist festgelegt
- Startzeit und -datum ist festgelegt
- Bei Kategorie „1 – Minor –“ wird die Probleminstanz gesetzt auf Service Besitzer
- Bei Kategorie „2 – Significant –“ wird die Probleminstanz gesetzt auf Probelem Manager
- Bei Kategorie „3 – Critical –“ wird die Probleminstanz gesetzt auf Führungsstab (welcher vom Problem Manager beraten wird)
- Nachdem die Probleminstanz bestimmt wurde wird der Problem Agent gesetzt auf Probleminstanz
- Am Ende der Aktivität wird der Problem Agent wieder gesetzt auf Problem Besitzer
Problemdiagnose
Die Problemdiagnose ist die komplizierteste Aktivität im Problem Management Prozess und dient der schnellen Lösung und Wiederherstellung der gestörten Service. In dieser Aktivität wird der Incident anhand der vorhandenen Informationen untersucht. Diese sind: Symptome der Störung, betroffene Service, CIs und User und außerdem zusätzliche Informationen über ähnliche Incidents, Fehler, Informationen aus der CMDB und angesammeltes Wissen der Techniker.
Die erste Aktion in diesem Unterprozess ist die Prüfung der korrekten Kategorisierung. (Wurde der relevante Service in Betracht gezogen? => Bei falscher Betrachtung wird der Incident auf „erfasst – akzeptiert“ gesetzt und zur erneuten Untersuchung zurückgegeben.)
Bei korrekter Kategorisierung wird geprüft ob der First Level Support korrekt abgewickelt wurde. (Wurden alle relevanten Checklisten bearbeitet? => Bei fehlerhaftem Support wird der Incident zurückgewiesen und der Status auf „klassifiziert“ gesetzt.)
Wurde der First Level Support korrekt abgewickelt so wird der Second Level Support das Problem Untersuchen und wenn möglich lösen. Falls eine Diagnose erstellt werden kann wird der Incident auf „erkannt” gesetzt.
Die Diagnose, sowie Vorgehensweisen (erfolgreich oder nicht) werden im Bericht festgehalten. Falls keine Lösung gefunden werden kann wird der Incident erneut eskaliert, auf „erkannt – fehlgeschlagen“ gestellt und an den externen Service Provider weitergeleitet (falls möglich). Die Incidentuntersuchung muss von vorne gestartet werden.
Aktivitätsspezifische Regeln
- Problem Agent wird gesetzt auf Diagnose Team
- Kategorisierung prüfen-
- Bei falscher Kategorisierung Staus auf „erfasst – akzeptiert“ setzen und Incident zur erneuten Untersuchung zurückgeben
- Prüfung ob First Level Support korrekt abgewickelt
- Falls First Level Support NICHT korrekt abgewickelt Staus auf „Klassifiziert“ setzen und Incident zurücksenden
- Diagnose des Problems durchführen
- Falls keine Diagnose möglich – Problem eskalieren
- Beschreibung der Diagnose und der Vorgehensweise im Bericht festhalten
- Problem Agent wird gesetzt auf Problem Besitzer
Problem-Registrierung von Bekannten Fehlern
Der Problem Besitzer prüft die Problemursache und (falls vorhanden) die Beschreibung des Workarounds. Beides wird für das Incident Management freigegeben. Ein Lösungsteam wird aus Mitarbeitern des Diagnose Teams zusammengestellt. Ebenfalls wird ein Terminplan für die Erstellung eines Lösungsvorschlages definiert.
Aktivitätsspezifische Regeln
- Start: Der Problembericht hat den Status dignified.
- Ende: Der Problembericht hat entweder den Status Fehler registriert oder fehlgeschlagen.
- Startzeit für die Lösungsfindung wird festgelegt
- Lösungsteam wird zusammengestellt
Problem-Lösungsfindung
Mit dieser Aktivität werden eine oder mehrere Lösung für das bestehende Problem definiert. Alle Alternativen werden im Change Request dokumentiert wovon eine wird als bevorzugte Alternative deklariert wird. Der Problem Besitzer darf das Lösungsteam verändern oder den Prozess stoppen.
Aktivitätsspezifische Regeln
- Problem Agent wird gesetzt auf Solution Team
- Beschreibung der bevorzugten Lösung sowie von Alternativen liefern
Problemwiederherstellung
Die Problemwiederherstellung erfolgt durch den Change Management Prozess. Diese Aktivität unterstützt die Wiederherstellung während Erstellung, Testen und Implementierung der Lösungen.
Am Ende der Aktivität wird der Problemstatus auf „Wiederhergestellt“ geändert.
Für den Fall dass benötigte CI noch nicht freigegeben sind wird auch der Release Management Prozess ausgelöst. Das Release Management ist für das Testen der CI und deren Funktionalität, sowie deren Betriebsfähigkeit und Kompatibilität zu anderen CI verantwortlich.
Dier Hautzweck dieser Aktivität ist die Genehmigung der Implementierung durch den Change Management Prozess.
Aktivitätsspezifische Regeln
- Ein Problem Builder wird aus der Gruppe der Fachexperten bestimmt.
- Ein Problem & Fallback Tester wird aus der Gruppe der Fachexperten bestimmt.
- Ein Problem Implementierter wird aus der Gruppe der Fachexperten bestimmt.
- Der Problem Builder darf nicht die gleiche Person sein wie der Problem & Fallback Tester.
- Der Problem Implementierer darf nicht die gleiche Person sein wie der Problem & Fallback Tester.
- Am Anfang der Aktivität wird der Problem Agent gesetzt auf Problem Builder.
- Nach der Aktion „building“ wird der Problem Agent gesetzt auf Problem & Fallback Tester.
- Falls die Aktion „Testen“ erfolgreich war wird der Problem Agent gesetzt auf Problem Implementierer.
- Der Implementierungsplan wird protokolliert und dem Change Management sowie dem Release Management zur Verfügung gestellt.
- Der Implementierungsplan wird getestet und die Testergebnisse werden im Problembericht gespeichert.
- Ein Fallback Plan wird protokolliert und zur Verfügung gestellt.
- Der Fallback Plan wird getestet und die Testergebnisse werden im Problembericht gespeichert.
- Funktionstestprozeduren werden beschrieben.
Problem Dokumentation
In dieser Aktivität wird die Problemlösung beschrieben. Hierbei werden Informationen aus Problembericht und Incidentbericht einbezogen.
Bei bestandener Prüfung erhält der Problembericht den Status „gelöst – dokumentiert“.
Aktivitätsspezifische Regeln
- Der Problem Agent (Welcher derzeit der Problem Implementierer ist) löst den Configuration Management Prozess aus um Informationen/Beziehungen in der CMDB zu aktualisieren.
- Der Problem Implementierer und der Configuration Librarian dürfen die gleiche Person sein.
- Der Problem Besitzer muss die Dokumentation bestätigen weshalb der Problem Agent bei Configuration Items gesetzt wird auf Problem Besitzer.
- Wird die Dokumentation NICHT akzeptiert, so wird der Problem Agent zurückgesetzt auf Problem Implementierer. Die Dokumentation muss verbessert werden.
- Prozesschnittstelle: Informationen über Service und CIs die von dem Problem betroffen waren werden mit Hilfe des Configuration Management in der CMDB aktualisiert.
Problem Evaluierung und Schließung (PIR)
In dieser Aktivität wird der Erfolg eines implementierten Problems bewertet. Ein sogenannter Post Implementation Review (PIR) wird durchgeführt und die Ergebnisse werden gespeichert. Falls der PIR nicht die erfolgreiche Lösung des Problems bestätigt muss ein eine Wiederholung des Problemprozesses ausgelöst werden. Abhängig von dem Ergebnis des PIR wird der Status des Problemberichts entweder auf „geschlossen – bestätigt“ oder „geschlossen – fehlgeschlagen“
Im PIR sollten die folgenden Fragen berücksichtigt werden:
- Erfüllt die Lösung die gewünschten Vorgaben?
- Wurde die Lösung rechtzeitig implementiert?
- Traten während des Problemprozesses weitere Incidents auf?
- Wurde die Lösung im Rahmen des zugeteilten Budgets durchgeführt?
- Wurde die Lösung dokumentiert und die CMDB aktualisiert?
- Wurde der Prozess von allen an der Lösung Beteiligten eingehalten?
- Passierte es während des Lösungsprozesses, dass für den Entscheidungsprozess notwendige Informationen fehlten?
- Wurden die Betroffenen laut RASCI Tabelle über de Fortschritt des Problems informiert?
Aktivitätsspezifische Regeln
- Am Anfang dieser Aktivität wird der Problem Agent gesetzt auf Problem & Fallback Tester.
- Wenn die Aufgabe „Testen“ erfolgreich ausfällt wird der Problem Agent geändert auf Problem Besitzer.
- Das Testergebnis muss gespeichert werden.
- Wenn die Aufgabe „Testen“ NICHT erfolgreich ausfällt wird der Problem Agent geändert auf Problem Implementierer.